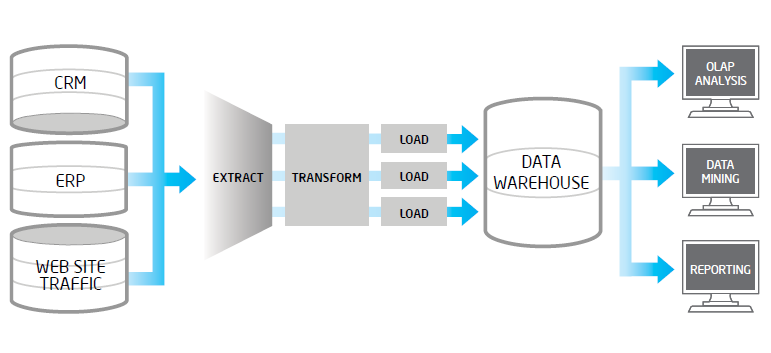
Extracción, Transformación y Carga
Extracción: consiste en obtener los
datos del sistema origen, realizando volcados completos o incrementales. En
ocasiones esta etapa suele apoyarse en un almacén intermedio, llamado ODS (Operational
Data Store), que actúa como pasarela entre los sistemas fuente y los sistemas
destino, y cuyo principal objetivo consiste en evitar la saturación de los
servidores funcionales de la organización.
Transformación: los
datos procedentes de repositorios digitales distintos no suelen coincidir en
formato. Por tanto, para lograr integrarlos resulta imprescindible realizar
operaciones de transformación. El objetivo no es otro que evitar duplicidades
innecesarias e impedir la generación de islas de datos inconexas. Las
transformaciones aplican una serie de reglas de negocio (o funciones) sobre los datos extraídos para convertirlos
en datos destino.
Carga: se trata de introducir los
datos, ya adaptados al formato deseado, dentro del sistema destino. En algunos
casos se sobreescribe la información antigua con la nueva, mientras que en
otros se guarda un historial de cambios que permite consultas retrospectivas en
el tiempo, así como revertir modificaciones. Para la carga masiva de datos
suele ser necesario desactivar temporalmente laintegridad referencial de la base de datos destino.

Estandarización y
limpieza de datos
La estandarización forma parte de los seis pasos necesarios
para llevar a cabo la limpieza de datos. Esta consiste en separar la
información en diferentes campos, así como unificar ciertos criterios para un
mejor manejo y manipulación de los datos.Tener datos estandarizados, consistentes y con calidad,
resulta muy útil y a veces de vital importancia para las empresas que utilizan
almacenes de datos. Un ejemplo de ello son aquellas organizaciones cuyos datos
referentes a sus clientes son de gran valor.
El manejo de los nombres y direcciones de los clientes no es
tarea fácil. Más del 50% de las compañías en Internet no pueden responder a las
necesidades de todos sus clientes y no se pueden relacionar con ellos a causa
de la falta de calidad en sus datos. Para comunicarse efectivamente con sus clientes, por
teléfono, por correo o por cualquier otra vía, una empresa debe mantener una
lista de sus clientes extraordinariamente limpia. Esto no solo provoca que
existan menos correos devueltos y más envíos precisos, sino que además, mejora
la descripción y análisis de los clientes, que se traduce en un servicio más
rápido y profesional.
Hay muchos ejemplos de aplicaciones basadas en la
información del cliente que necesitan que sus datos, y principalmente sus
direcciones tengan integridad, algunos de ellos son:
Sistemas CRM (Customer Relationship Management, Gestión de
las Relaciones con el Cliente)
E-Business (Negocios electrónicos) Call Centers (Oficina o
compañía centralizada que responde llamadas telefónicas de clientes o que hacen
llamadas a clientes (telemarketing)) Sistemas de Marketing.
limpieza de datos, es el acto de
descubrimiento, corrección o eliminación de datos erróneos de una base de
datos. El proceso de data cleansing permite identificar datos incompletos,
incorrectos, inexactos, no pertinentes, etc. y luego substituir, modificar o
eliminar estos datos sucios "data duty". Después de la limpieza, la
base de datos podrà ser compatible con otras bases de datos similares en el
sistema.
Las inconsistencias descubiertas, modificadas o eliminadas pueden
haber sido causado por: las definiciones de diccionario de datos diferentes de
entidades similares, errores de entrada del usuario y corrupción en la
transmisión o el almacenaje. La Limpieza de datos se diferencia de la validación de datos
"data validation", en que la validación de datos cumple la función de
rechazar los registros erróneos durante la entrada al sistema. El proceso de
data cleansing incluye la validación y además la corrección de datos, para
alcanzar datos de calidad "Data quality".
Primera carga y procesos de actualización
Estructura física del Almacén de Datos
La estructura física o carga se puede presentar cualquiera de las siguientes
configuraciones:
Arquitectura centralizada. Todo el Almacén de datos se
encuentra en un único servidor.
Arquitectura distribuida. Los datos del Almacén se reparten
entre varios servidores. Asignando cada servidor a uno o varios temas lógicos.
Arquitectura distribuida por niveles. Refleja la estructura
lógica del Almacén, asignando los s ervidores en función del nivel de agregación
de los datos que contienen. Un servidor está dedicado
para los datos de
detalle, otro para los resumidos y otro para los muy resumidos.
Cuando los datos muy resumidos se duplican en varios
servidores para agilizar el acceso se habla de Supermercados de datos
(Data Marts).
El acceso a los datos (Estructura lógica del Almacén de Datos)
La estructura lógica de un Almacén de Datos está compuesta
por los siguientes niveles:
Metadatos.
Describen la estructura de los datos contenidos en el almacén.
1.
Están en una dimensión distinta al resto de
niveles.
Datos detallados
actuales. Obtenidos directamente del procesado de los datos.
1.
Forman el nivel más bajo de detalle.
2.
Ocupan mucho espacio.
3.
Se almacenan en disco, para facilitar el acceso.
Datos detallados
históricos. Igual que los anteriores, pero con datos correspondientes al
pasado.
1.
Se suelen almacenar en un medio externo, ya que
su acceso es poco frecuente.
Datos ligeramente
resumidos. Primer nivel de agregación de los datos detallados actuales.
Corresponden a
consultas habituales.
1.
Se almacenan en disco.
2.
Datos muy resumidos. Son el nivel más alto de
agregación.
3.
Corresponden a consultas que se realizan muy a
menudo y que se deben obtener muy rápidamente.
4.
Suelen estar separados del Almacén de datos,
formando Supermercados de Datos (Data Marts).
No hay comentarios.:
Publicar un comentario